Who is the most powerful model? How should it be judged?
From the Thousand-Group Battle to the Battle of Sharing, and now to the current battle of large models, the Hundred-Model War is unfolding in full swing, with each side holding their own opinions.
Today, I will combine data from third-party platforms to rank the currently popular large models based on five major dimensions of capabilities: comparing and analyzing AI models on key performance indicators (including quality, price, output speed, latency, context window, etc.).
Here are the highlights of the six key indicators:
- Quality Index: Used to evaluate the performance of models in various tasks and benchmark tests, a higher score indicates better model performance.
- Output Speed: Measures the speed at which the model generates output; a higher output speed indicates stronger processing capabilities.
- Price: Represents the cost of the model; a lower price indicates higher cost-effectiveness.
- Latency: Refers to the time interval between sending a request and receiving the first response; lower latency indicates faster model response.
- Context Window: Indicates the limit on the number of tokens the model can consider when processing text; a larger context window helps the model better understand and generate text.
- Total Response Time: The time elapsed from sending a request to receiving the complete output result, taking into account factors such as latency and output speed.
These key indicators can help users comprehensively evaluate and compare the performance and characteristics of different AI models, thereby selecting the model that best suits specific task requirements.
- The higher the quality index, the better. There is a trade-off between quality, output speed, and price. The quality index represents the relative performance in the field of chatbots, MMLU, and MT-Bench.
- The speed metric represents the number of tokens generated per second during model inference.
- The price metric represents the cost per million tokens. There are speed differences between models, and quality and price do not necessarily correlate.
- The total response time represents the time required to receive output for 100 tokens, calculated based on latency and output speed metrics.
- The latency metric represents the time required to receive the first token. The total response time varies with the increase in input token length. There is a trade-off between speed and price, and a relationship between latency and output speed.
- The total response time varies with the increase in input token length. There are speed differences between models. The total response time represents the time required to receive output for 100 tokens. There are differences in total response time between models.
The ranking of AI models based on different metrics is as follows:
First, Quality Index:
The higher the score, the better. The quality index of large AI models is usually evaluated based on their performance in various benchmark tests and tasks. A higher quality index score indicates better performance in all aspects. These performance metrics may include accuracy, fluency, logic, etc., in tasks such as natural language processing, text generation, dialogue systems, etc. A higher quality index means the model performs better in various tasks. When choosing to use large models, the quality index is an important reference metric that can help users evaluate the overall performance and suitability of the model.
- GPT-4o
- Claude 3.5 Sonnet
- Gemini 1.5 Pro
- GPT-4 Turbo
- Claude 3 Opus
- Gemini 1.5 Flash
- Llama 3 (70B)
- Command-R+
- Claude 3 Haiku
- Mixtral 8x22B
- Llama 3 (8B)
- Mixtral 8x7B
- GPT-3.5 Turbo
Second, output speed:
The output speed of large AI models is usually influenced by multiple factors, including the complexity of the model, the number of parameters, computational resources, and the level of optimization. Generally speaking, large models with more parameters and complex computation processes may have slower output speeds. Larger models typically require more computational resources and time to process input data and generate output, thus their output speed may be somewhat affected. However, some large models may improve output speed through optimization algorithms, parallel computing, and other technologies to enhance performance and efficiency. In practical applications, it is necessary to consider factors such as the model’s output speed, accuracy, and latency comprehensively in order to select the model that best suits the specific task.
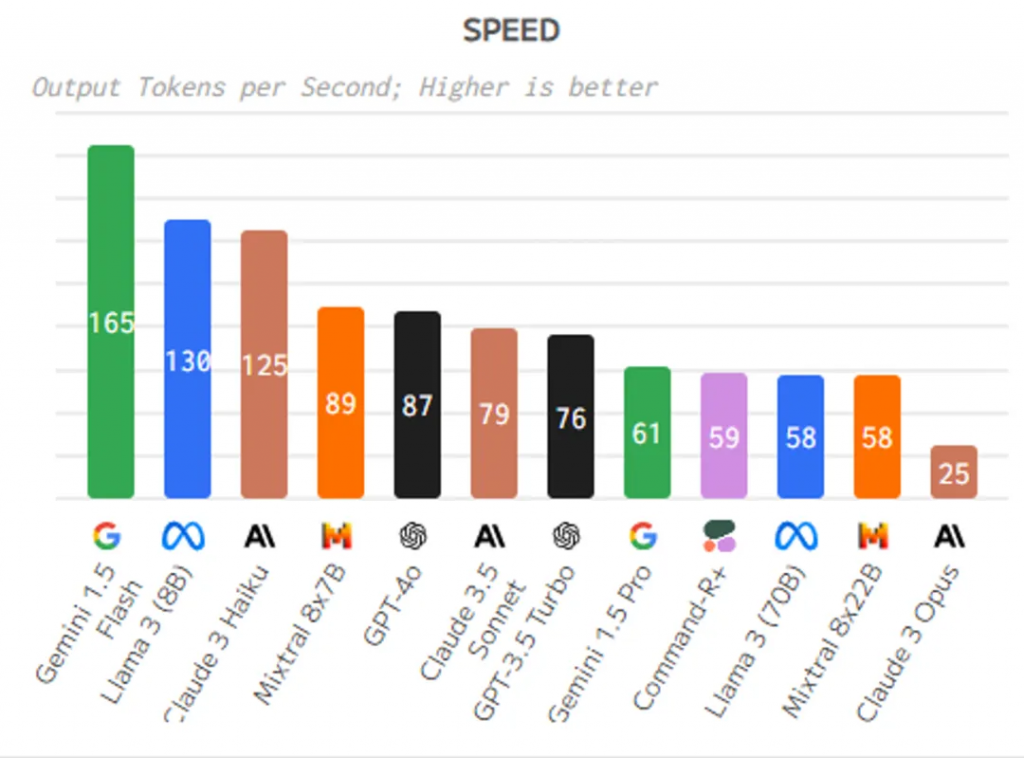
- Gemini 1.5 Flash
- Llama 3 (8B)
- Claude 3 Haiku
- Mistral 7B
- Mixtral 8x7B
- GPT-4o
- Claude 3.5 Sonnet
- GPT-3.5 Turbo
Third, large model token pricing:
The price of large AI models is usually influenced by multiple factors, including the complexity of the model, the number of parameters, training costs, computational resources, and more. Large models typically require more computational resources and time for training and deployment, hence their prices may be higher. Additionally, some large models may require specialized hardware devices or cloud computing services to support their operation, which can also increase costs. When choosing to use large models, it is important to consider a balance between price and performance to ensure cost control while meeting requirements. Different providers and services may have varying pricing strategies and models, so a comprehensive evaluation and comparison are necessary when selecting large models.
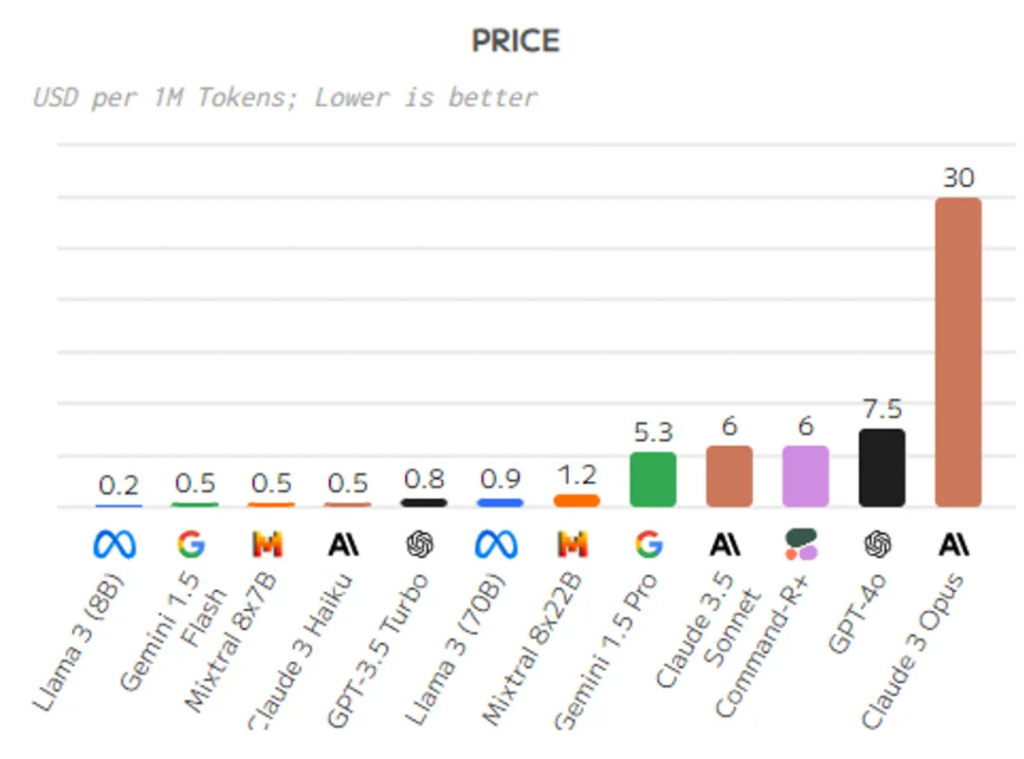
- Llama 3 (8B)
- Gemini 1.5 Flash
- Mixtral 8x7B
- Claude 3 Haiku
- GPT-3.5 Turbo
- Llama 3 (70B)
- Mixtral 8x22B
- GPT-4 Turbo
- Claude 3 Opus
Fourth, large-scale model context window:
The context window refers to the limit on the number of tokens that a model can consider simultaneously when processing text in natural language processing. In other words, the context window represents the range of the length of the input text that the model can see when generating output. A larger context window means that the model can take into account more contextual information, thus better understanding and generating text. In certain tasks such as information retrieval and reasoning, a larger context window may lead to better performance. Therefore, the context window is one of the important indicators for evaluating the capability and performance of a model.
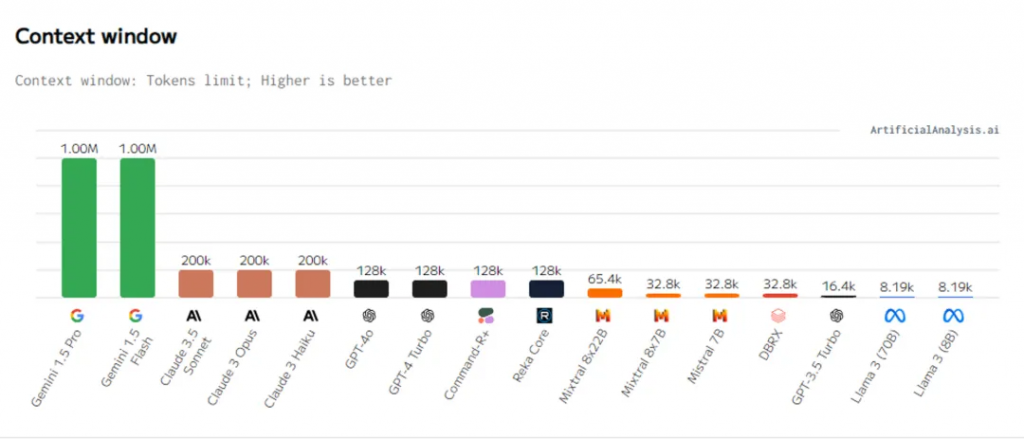
- Gemini 1.5 Pro
- Gemini 1.5 Flash
- Claude 3.5 Sonnet
- Claude 3 Opus
- Claude 3 Haiku
- GPT-4o
- GPT-4 Turbo
- Command-R+
- Reka Core
Fifth, total response time:
The total response time of large AI models is usually influenced by multiple factors, including the complexity of the model, the number of parameters, computational resources, input data size, and more. Total response time refers to the time it takes from sending a request to receiving the complete output result. For large models, due to their complexity and high computational requirements, the total response time may be longer. However, some large models may reduce the total response time through optimization algorithms, parallel computing, and other technologies to improve performance and efficiency. In practical applications, it is necessary to comprehensively consider factors such as the total response time, accuracy, and latency of the model in order to choose the model that best suits the specific task.
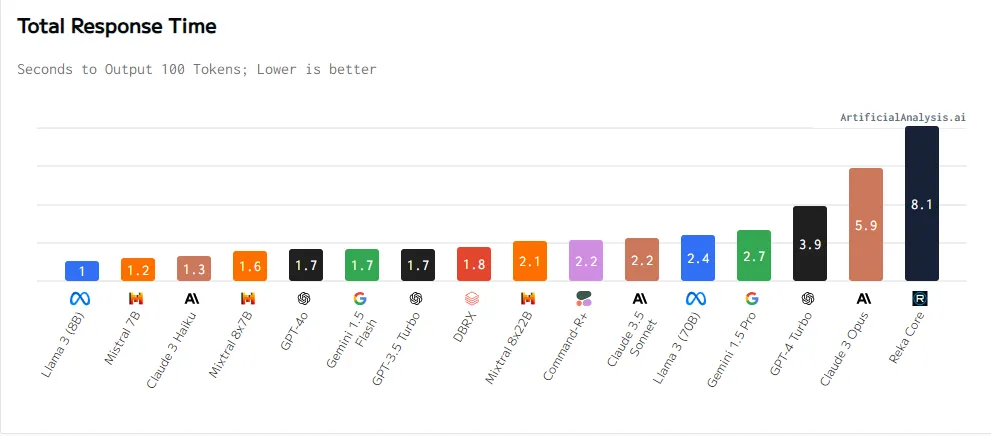
- Llama 3 (8B)
- Mistral 7B
- Claude 3 Haiku
- Gemini 1.5 Flash
- GPT-3.5 Turbo
- Mixtral 8x7B
- GPT-4o
- Claude 3.5 Sonnet
Sixth, Delay Sorting:
Furthermore, sorting AI models based on delay (in seconds) is as follows: Large AI models typically have higher delays because these models need to process more parameters and more complex calculations. Large models usually require more computational resources and time to process input data and generate output. Therefore, compared to small models, the delay of large models may be longer. However, some large models may reduce delays through optimization and parallel processing technologies to improve performance and efficiency. When choosing to use large models, it is necessary to balance the relationship between performance and delay to meet the specific requirements of the application.
- Mistral 7B
- Mixtral 8x22B
- Llama 3 (8B)
- Mixtral 8x7B
- GPT-3.5 Turbo
- Command-R+
- Llama 3 (70B)
- DBRX
- GPT-4o
- Claude 3 Haiku
- GPT-4 Turbo
- Claude 3.5 Sonnet
- Gemini 1.5 Pro
- Gemini 1.5 Flash
- Reka Core
- Claude 3 Opus
======================================
According to the ranking based on different indicators, we can have a clearer understanding of the performance of various AI models on key performance metrics.
Based on the ranking results, the highlights of the six key indicators can be summarized as follows:
- Quality Index: GPT-4o and Claude 3.5 Sonnet perform the best in terms of quality index, scoring high and demonstrating outstanding performance in various tasks and benchmark tests.
- Output Speed: Gemini 1.5 Flash and Llama 3 (8B) excel in output speed, showing high processing power and speed.
- Price: Llama 3 (8B) and Gemini 1.5 Flash perform well in terms of price, offering lower prices and higher cost-effectiveness.
- Latency: Mistral 7B and Mixtral 8x22B perform well in terms of latency, with fast response times.
- Context Window: Gemini 1.5 Pro and Gemini 1.5 Flash have larger context windows, which help the models better understand and generate text.
- Total Response Time: Llama 3 (8B) and Mistral 7B stand out in total response time, being able to quickly generate complete output results.
In conclusion, users can choose the most suitable AI model based on specific needs and key indicators of interest. This concludes the entire text.
Leave a Reply